Dân Chúa ? | Liên Lạc | ![[Valid RSS]](images/rss.png) RSS Feeds
RSS Feeds
Tháng 10/2020

Bài Mới
- Hậu quả cuộc bầu cử 2020: Giới truyền thông mất mặt, đảng Dân Chủ thoái trào
- Hậu quả cuộc bầu cử 2020: Những ảnh hưởng với các chính sách Công Giáo
- Nghi Thức Trừ Tà Trên Đà Gia Tăng, Đặc Biệt Là Sau Những Cuộc Biểu Tình
- Tổng thống Trump tuyên bố chiến thắng và cảnh báo trò gian lận
- ĐTC ban hành tự sắc liên quan đến việc lập các hội dòng giáo phận
- Tòa Thánh kêu gọi bảo vệ tính chất thánh thiêng sự sống con người
- Giáo hội Pháp phản đối lệnh hạn chế cử hành Thánh lễ có giáo dân tham dự
- Giáo hội Pakistan vui mừng vì Arzoo, 13 tuổi, bị bắt cóc và ép theo Hồi giáo, được giải cứu
- ĐTC Phanxicô: Cầu nguyện là bánh lái hướng dẫn cuộc đời chúng ta
- ĐTC và các giám mục trên thế giới đau buồn về các vụ tấn công ở Vienna
- Một linh mục California đã được huyền chức sau khi không công nhận Đức Thánh Cha Phanxicô
- Ở đất nước nơi từng được xem là Công Giáo nhất hoàn cầu, linh mục nào cử hành thánh lễ là đi tù
- Không khí cuộc bầu cử ngày 03 tháng 11. Các nước Á Châu hướng về Hoa Kỳ hồi hộp theo dõi kết quả
- Đức cha Mandagi kêu gọi giải quyết vấn đề Paqua bằng đối thoại
- HĐGM Bắc Phi mời gọi các tín hữu xây dựng một thế giới tốt đẹp hơn
- Các tổ chức tôn giáo Philippines kêu gọi điều tra quốc tế về vi phạm nhân quyền
- ĐHY Schönborn kêu gọi cầu nguyện cho các nạn nhân trong các vụ nổ súng ở Vienna
- Sáng kiến lần hạt toàn cầu cầu nguyện cho các thai nhi đã bị phá bỏ
- ĐTC dâng lễ cầu nguyện cho các tín hữu qua đời
- Làn sóng phản đối gia tăng tại Pakistan sau khi Toà án đồng thuận với vụ bắt cóc trẻ vị thành niên Công giáo
- Tuyên bố chung giữa Công giáo và Hồi giáo tại Bỉ bày tỏ mong muốn tôn trọng lẫn nhau
- Tính Thành Hiệu Của Bí Tích Giải Tội Tin Lành
- Thủ đô Vienna của Áo bị khủng bố Hồi Giáo tấn công
- Nguyên văn lá thư của Tòa Thánh giải thích tuyên bố của Đức Phanxicô về việc sống chung đồng tính
- Tòa Bạch Ốc đã bị bao vây bởi những người chống Tổng thống Trump
- Đức Tổng Giám Mục Philadelphia cầu nguyện, kêu gọi hòa bình sau nhiều ngày bất ổn
- Biden chào hàng ‘cảm hứng’ đức tin Công Giáo, mặc dù tiếp tục ủng hộ phá thai và đòi hạn chế tự do tôn giáo
- Tòa án Brazil cấm một tổ chức vận động phá thai dùng tên “Công giáo”
- Một ngàn giáo xứ chầu Thánh Thể trong ngày Hoa Kỳ bầu Tổng thống
- ĐTC bổ nhiệm Đức tổng giám mục Tomasi làm đặc sứ của ngài tại Hội Hiệp sĩ Malta
- Lễ phong chân phước cho cha Michael McGivney, đấng sáng lập Hội Hiệp sĩ Columbus
- Ý Nghĩa Bức Họa Chính Thức Về Các Thánh Tử Đạo Việt Nam
- Ngọn đuốc cho đời - Vì sao cho đạo
- Lễ Các Thánh Nam Nữ khai mạc tháng cầu cho các đẳng linh hồn tại Vatican
- Về Cội
- Tự Tình “Tháng Mười Một Các Đẳng”
- Phép lạ ngoạn mục, Y khoa không thể giải thích dẫn đến lễ Tuyên Chân Phúc cho Cha McGivney hôm 31/10
- Giáo hội và thế giới cần tình mẫu tử và nữ tính của Đức Mẹ Maria
- Phim mới về Cha Thánh Maximilian Kolbe
- Vị Hồng Y tân cử đang trông coi một Giáo phận chỉ có ba linh mục!
Sách Online



Trí khôn nhân tạo sẽ giúp Văn Khố Mật của Tòa Thánh trở thành hữu dụng
§ Vũ Văn An
Theo ký giả Sam Keam, Văn Khố Mật của Tòa Thánh (VKMTT) là một sưu tập lịch sử vĩ đại nhất trên thế giới. Nhưng hiện nó cũng là một sưu tập vô dụng nhất.
Sự vĩ đại của nó là điều hiển nhiên. Nằm bên trong các tường thành Vatican, cạnh Thư Viện Tông Tòa và ngay phía bắc Nhà Nguyện Sistine, Văn Khố Mật của Tòa Thánh chứa 53 dặm (nếu chải dài) các kệ tài liệu có từ hơn 12 thế kỷ nay. Nó chứa những tài liệu qúy giá như sắc chỉ phạt tuyệt thông Martin Luther và lời cầu khẩn của Nữ Hoàng Mary, Tô Cách Lan, gửi Đức GH Sixtô V trước khi bà bị xử tử. Về tầm và cỡ, sưu tập này gần như không có đối thủ.
Nói thì nói thế, nhưng Văn Khố Mật của Tòa Thánh không mấy có ích đối với các học giả ngày nay, vì nó rất khó với tới. Trong số 53 dặm tài liệu nói trên, chỉ có khoảng vài milimét đã được chụp bằng máy rọi (scanned) và sẵn sàng được sử dụng trực tuyến. Tuy nhiên, nếu nói đến việc chuyển thành bản văn vi tính để có thể tìm tòi, thì số này còn ít hơn nữa. Nếu muốn sử dụng bất cứ điều gì khác, bạn phải xin một phép đặc biệt, tự tới tận Rôma, và tự tay mở từng trang giấy.
Tin vui là một dự án mới sắp sửa thay đổi tất cả các phiền toái trên. Được biết dưới tên In Codice Ratio, nó sử dụng một phối hợp giữa trí khôn nhân tạo (artificial intelligence) và phần mềm Nhận Biết Ký Tự Quang Học (optical-character-recognition [OCR]) để lục lạo các bản văn bị quên lãng này và biến việc ghi chép chúng thành sẵn sàng được sử dụng lần đầu tiên. Nếu thành công, kỹ thuật này cũng sẽ mở được man vàn các tài liệu khác tại các văn khố khắp thế giới.
Nhận Biết Ký Tự Quang Học đã từng được sử dụng để rọi chụp các cuốn sách và các tài liệu khác trong nhiều năm qua, nhưng nó không thích hợp bao nhiêu đối với các tư liệu tại Văn Khố Mật của Tòa Thánh. Nhận Biết Ký Tự Quang Học truyền thống tách các chữ thành một loạt các hình mẫu tự (letter-image) bằng cách nhìn vào khoảng cách giữa các mẫu tự. Sau đó, nó so sánh từng hình chữ này với kho mẫu tự trong ký ức của nó. Sau khi quyết định mẫu tự nào xứng nhất đối với hình, phần mềm sẽ phiên dịch mẫu tự thành mã số vi tính (ASCII) và nhờ thế, biến bản văn thành tìm tòi được.
Tuy nhiên, diễn trình trên thực sự chỉ hoạt động được trên bản văn thuộc loại sắp chữ (typeset text). Nó tỏ ra lười lĩnh đối với bất cứ điều gì viết bằng tay, như đại đa số tài liệu xưa của Vatican. Sau đây là một thí dụ thuộc đầu thập niên 1200, viết bằng loại chữ gọi là chữ thường Caroline, trông giống như một phối hợp giữa thư pháp (calligraphy) và chữ thảo (cursive):

Vấn đề chính trong thí dụ trên là thiếu khoảng cách giữa các mẫu tự. Nhận Biết Ký Tự Quang Học không thể nói chỗ nào một mẫu tự chấm dứt và một mẫu tự khác bắt đầu, và do đó, không biết có bao nhiêu mẫu tự. Kết quả là máy điện toán không làm việc được, đôi khi người ta gọi sự kiện này là nghịch lý Sayre: phần mềm Nhận Biết Ký Tự Quang Học cần phân một chữ thành các mẫu tự cá thể trước khi có thể nhận ra chúng, nhưng trong các bản văn viết tay với các mẫu tự nối liền nhau, phần mềm cần nhận ra các mẫu tự để có thể phân đoạn chúng. Đây là một vòng luẩn quẩn.
Một số khoa học gia vi tính đã cố gắng giải quyết bế tắc này bằng cách làm cho Nhận Biết Ký Tự Quang Học nhận ra trọn các chữ thay vì mẫu tự. Điều này có thể thành công về phương diện kỹ thuật: các máy vi tính đâu có “lưu ý” là chúng phân tích các chữ hay các mẫu tự. Nhưng thiết lập và cho chạy các hệ thống này đâu phải chuyện lơ mơ, vì chúng đòi một kho ký ức khổng lồ. Thay vì ít chục mẫu tự a,b,c, các hệ thống này phải nhận diện hình ảnh của hàng ngàn hàng vạn các chữ thông thường. Điều này có nghĩa bạn cần cả hàng trung đội học giả có chuyên môn về tiếng La Tinh thời Trung Cổ để rà xét các tài liệu cổ và chụp hình ảnh của từng chữ. Thực vậy, bạn cần một vài hình ảnh của từng chữ vì có thể có những nét chữ kiểu cách (quirks) trong lối viết tay hay ánh sáng không đủ và nhiều biến tố khác. Đây quả là một nhiệm vụ ghê gớm.
Dự án In Codice Ratio vượt qua các nan đề trên nhờ cách tiếp cận mới với Nhận Biết Ký Tự Quang Học viết tay. Bốn nhà khoa học chính phía sau dự án này: Paolo Merialdo, Donatella Firmani, và Elena Nieddu của Đại Học Roma Tre, và Marco Maiorino của Văn Khố Mật của Tòa Thánh, đã vượt qua nghịch lý Sayre bằng một cải tiến có tên là phân đoạn ráp hình (jigsaw segmentation). Diễn trình này phân các chữ không phải thành các mẫu tự nhưng thành một thứ gần như nét bút (pen stroke) cá thể hơn. Nhận Biết Ký Tự Quang Học thực hiện việc này bằng cách chia mỗi chữ thành một loạt giải dọc và ngang và tìm những điểm tối thiểu (minimum): những phần mỏng hơn, nơi có ít mực hơn. Lúc ấy, phần mềm sẽ lách tới các mẫu tự ở những điểm này. Kết quả là một loạt các mảnh của trò chơi ráp nối:

Tự chúng, các mảnh ráp nối chẳng hữu dụng bao nhiêu. Nhưng phần mềm có thể tạo khối (chunk) chúng nhiều cách khác nhau để làm ra các mẫu tự. Nó chỉ cần biết nhóm khối nào đại diện cho các mẫu tự thực sự và nhóm nào không.
Để dạy phần mềm điều trên, các nhà nghiên cứu đã nhờ một nguồn giúp đỡ không bình thường: các học sinh trung học. Nhóm đã tuyển các học sinh tại 24 trường ở Ý để thiết lập các kho ký ức (memory banks) cho dự án. Các học sinh vào một trang mạng, nơi họ thấy một màn hình với ba phần:
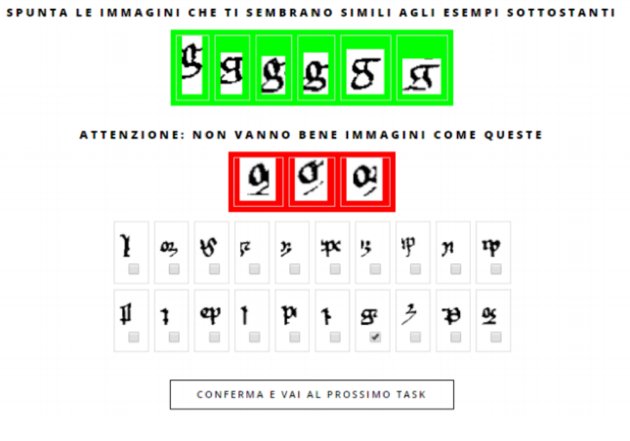
Vạch xanh ở trên cùng chứa thí dụ các mẫu tự rõ ràng, sạch sẽ lấy từ một bản văn La Tinh thời Trung Cổ, trong trường hợp này là mẫu tự g. Vạch đỏ ở giữa chứa các thí dụ không xác thực của mẫu tự g, điều mà các nhà khoa học của Codice gọi là “các người bạn giả mạo” (“false friends”). Khung phía cuối cùng là phần cốt lõi của chương trình. Mỗi hình ở đấy được hợp thành bởi một ít các mảnh ráp nối mà Nhận Biết Ký Tự Quang Học đã tạo khối với nhau, tức được nó đoán là các mẫu tự có giá trị. Các học sinh sẽ phán đoán các cố gắng của Nhận Biết Ký Tự Quang Học, bằng cách cho nó hay dự đoán nào tốt, dự đoán nào không tốt. Các em làm thế bằng cách so sánh mỗi hình với các mẫu tự tuyệt hảo ở vạch xanh và “click” một hộp kiểm soát khi thấy một mẫu tự xứng hợp.
Với từng hình và từng cú “click” như thế, các học sinh đã dạy phần mềm điều mà mỗi một trong 22 mẫu tự của chữ La Tinh Trung Cổ (a-i, l-u, và một vài hình thức thay thế nhau của s và d) trông giống như.
Việc thiết lập đòi phải có nhập lượng chuyên môn: các học giả phải chọn các thí dụ hoàn hảo ở vạch xanh, cũng như các người bạn giả mạo ở vạch đỏ. Nhưng một khi họ đã làm được việc này, thì không cần phải làm thêm nữa. Thậm chí các học sinh không cần phải biết đọc chữ La Tinh. Các em chỉ cần ghép các mẫu hình. Thoạt đầu, “ý tưởng mời các em học sinh trung học tham gia bị coi là điên rồ”, Merialdo nói thế; ông vốn nghĩ ra In Codice Ratio. “Nhưng nay, máy học được là nhờ các cố gắng của các em. Tôi rất thích điều này: sự đóng góp nhỏ nhoi và đơn giản của nhiều người quả thực đã có thể góp phần giải quyết một vấn đề phức tạp”.
Dĩ nhiên, cuối cùng, các học sinh cũng đã đứng qua một bên. Khi các em đã “bỏ phiếu ‘yes’” cho đủ các thí dụ, phần mềm sẽ bắt đầu tạo khối cho các mảnh ráp nối một cách độc lập và tự phán đoán lấy các mẫu tự ở đấy. Phần mềm đã trở thành một chuyên viên, nó trở thành trí khôn nhân tạo.
Ít nhất, cũng được kể như một thứ trí khôn đó. Nhưng việc tạo khối các mảnh ráp nối để trở thành các mẫu tự có giá trị chưa đủ. Máy tính vẫn cần những dụng cụ phụ trội để gỡ rối các khúc mắc của bản văn viết tay. Hãy tưởng tượng bạn đang đọc một lá thư rồi bỗng gặp hàng chữ này:

Với chúng, đây là chữ “clear” hay chữ “dear”? Khó mà nói được, vì các nét viết tạo thành chữ “d” và “cl” gần như giống nhau. Phần mềm Nhận Biết Ký Tự Quang Học phải đối đầu với cùng một nan đề, nhất là với kiểu viết kiểu cách như chữ Caroline nhỏ xíu. Bạn hãy ráng giải mã chữ này:
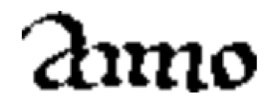
Sau khi lượt qua các kết hợp ráp nối khác nhau, Nhận Biết Ký Tự Quang Học đành bó tay. Các dự đoán là aimo, amio, aniio, aiino, và thậm chí cả bài hát Old MacDonald’s Farm, aiiiio nữa. Nhưng thực ra, đây là chữ anno, tiếng La Tinh có nghĩa là “năm” và phần mềm chỉ nắm được hai mẫu tự a và o. Còn 4 cột song song ở giữa, nó bỏ cuộc!
Để giải quyết nan đề trên, nhóm In Codice Ratio phải dạy phần mềm một số hiểu biết thường thức, thứ trí khôn thực tiễn. Họ thành lập một bộ gồm 1 triệu rưỡi các chữ La Tinh đã được kỹ thuật số hóa, và khảo sát chúng trong những kết hợp từng hai hay ba mẫu tự một. Từ việc này, họ xác định kết hợp mẫu tự nào là thông thường, và kết hợp nào không. Phần mềm Nhận Biết Ký Tự Quang Học sau đó có thể sử dụng các thống kê này để gán các khả thể cho các dây mẫu tự khác nhau. Kết quả, phần mềm học được rằng nn chắc chắn đúng hơn iiii nhiều.
Với những cải tiến trên được đưa vào, Nhận Biết Ký Tự Quang Học nay sẵn sàng tự đọc được một số bản văn. Nhóm quyết định nạp cho nó một số tài liệu từ Danh Bộ Vatican, tức tiểu bộ 18,000 trang của Văn Khố Mật của Tòa Thánh gồm các thư từ của các nhà vua ở Âu Châu về các vấn đề luật lệ và nhiều vấn đề khác.
Kết quả ban đầu khá lẫn lộn. Trong các bản văn được sao chụp cho tới nay, trọn 1 phần 3 các chữ chứa một hay nhiều lỗi in ấn, ở những chỗ Nhận Biết Ký Tự Quang Học đoán sai mẫu tự. Nó đại khái đọc như thế này trong tiếng Anh: “If yov were tryinj to read those lnies in a bock, that would gct very aiiiioying” (nếu bạn cố gắng đọc những giòng này trong một cuốn sách, thì bạn có thể rất bực mình). (những lỗi in ấn thông thường nhất bao gồm sự lẫn lộn m/n/i và một cặp thường bị lẫn lộn nữa là mẫu tự f và hình thức xưa và viết dài ra của mẫu tự s). Tuy thế, phần mềm đã có thể lấy đúng đến 96 phần trăm các mẫu tự viết tay. Thậm chí “ngay những sao chép thiếu sót cũng cung cấp đủ tư liệu và ngữ cảnh về bản chép tay đang có” để có thể hữu ích, Merialdo quả quyết như thế.
Giống mọi trí khôn nhân tạo khác, phần mềm sẽ được cải tiến với thời gian, với đà nó ngấu nghiến nhiều bản văn hơn. Điều đáng lưu ý hơn nữa là chiến lược tổng quát của In Codice Ratio rất dễ thích ứng để đọc các bản văn bằng các ngôn ngữ khác. Điều này có thể thực hiện cho các tài liệu viết tay điều mà Google Books làm cho các tài liệu in ấn: mở được các lá thư, các tập san, nhật ký, và các văn bản khác cho các nhà nghiên cứu khắp thế giới, làm cho cả việc đọc các tài liệu này lẫn việc tìm tòi các tư liệu có liên quan trở thành dễ dàng hơn nhiều.
Nhưng, theo Rega Wood, một sử gia về triết học và là 1 nhà chuyên môn về cách viết tay ngày xưa ở Đại Học Indiana, việc dựa vào trí khôn nhân tạo luôn có các giới hạn của nó. Bà cho biết: “vấn đề lớn là việc các thủ bản do các vị chuyên nghiệp viết nhưng được các vị không chuyên nghiệp sao chép lại” vì việc viết tay và hình dáng các mẫu tự thay đổi rất nhiều trong các tài liệu này, làm việc dạy Nhận Biết Ký Tự Quang Học trở thành khó khăn hơn. Ngoài ra, trong các trường hợp chỉ có một số nhỏ mẫu tư liệu để làm việc, “thì không dùng kỹ thuật này, không những việc sao chụp sẽ chính xác hơn mà còn nhanh hơn”.
Xin lỗi Dan Brown, chữ “mật” trong danh xưng Văn Khố Mật của Tòa Thánh không hề có nghĩa là giấu giếm hay thông đồng chi. Nó chỉ có nghĩa văn khố là tài sản riêng của vị giáo hoàng mà thôi; “văn khố riêng” có lẽ thích đáng hơn để dịch danh xưng nguyên thủy Archivum Secretum. Tuy nhiên, mới gần đây, Văn Khố Mật của Tòa Thánh cũng có thể mật đối với hầu hết thế giới, vì bị khóa kín và phần lớn chẳng mấy ai với tới. Theo Merialdo, “điều kỳ diệu đối với chúng tôi là đem các bản viết tay này trở lại sự sống và làm cho việc thấu hiểu chúng sẵn có đó đối với mọi người”.
 Đọc nhiều nhất
Đọc nhiều nhất  Bản in 10.05.2018 17:54
Bản in 10.05.2018 17:54
Cơ Sở Truyền Thông & Nguyệt San Dân Chúa.
PO Box 1419 Gretna, LA 70053-5440, USA. Đt: (504) 392-1630.
Email: Dân Chúa |
webmaster |